
2026-03-20 Update
This piece quickly became out of date with the rapid evolution of the agentic coding meta. Plan mode, Codex, setting agents loose in the cloud, etc. Use it as a window into the past :]
Introduction
I don’t think I have hand written a line of code in the past two months. When I started using large language models (LLMs; what many refer to as AI broadly) as part of my coding workflow, I would have my code editor on one side of the screen and a browser with ChatGPT on the other. I would think about what I wanted my program to do, bounce my ideas off the AI, and have it draft some code. Often I would end up taking or leaving its ideas and write much of the code myself. Now? I am fully in the matrix, perhaps never to return.
"I don't want to remember nothing—NOTHING, you understand? And I want to be rich. You know, someone important, like an actor." —Cypher, The Matrix
A year from now I probably won’t remember nothing when it comes to code syntax. And my wife and mom think I’m important so I have that going too. I’m some combination of architect and sheep herder now, planning a project and then building the fences that keep my flock of robot engineers from straying. These robot engineers, they would smoke me at Jeopardy or competitive coding but they can be terrible at knowing what they don’t know. That realization is what allowed me to turn the corner from ping-ponging ideas and copy/pasting code to being an AI agent supervisor.
A Better Way to Vibe
If you’ve tried building something with an AI agent — vibe coding they call it — that takes more than one or two prompts, you have experienced the doom loop.
“Looks good, almost there. I wanted this part to do this, not that.”
“Numbers still don’t look right, they should look like this.”
“Getting this error, please fix.”
“You hardcoded something to fix the error and now the program is not doing what it should. Please fix.”
“Getting this error, please fix.”
You do a few more of those and then you might revert to your last working commit or just scrap the project and start over. What went wrong? You were vibing instead of architecting and sheep herding. I present a better way:
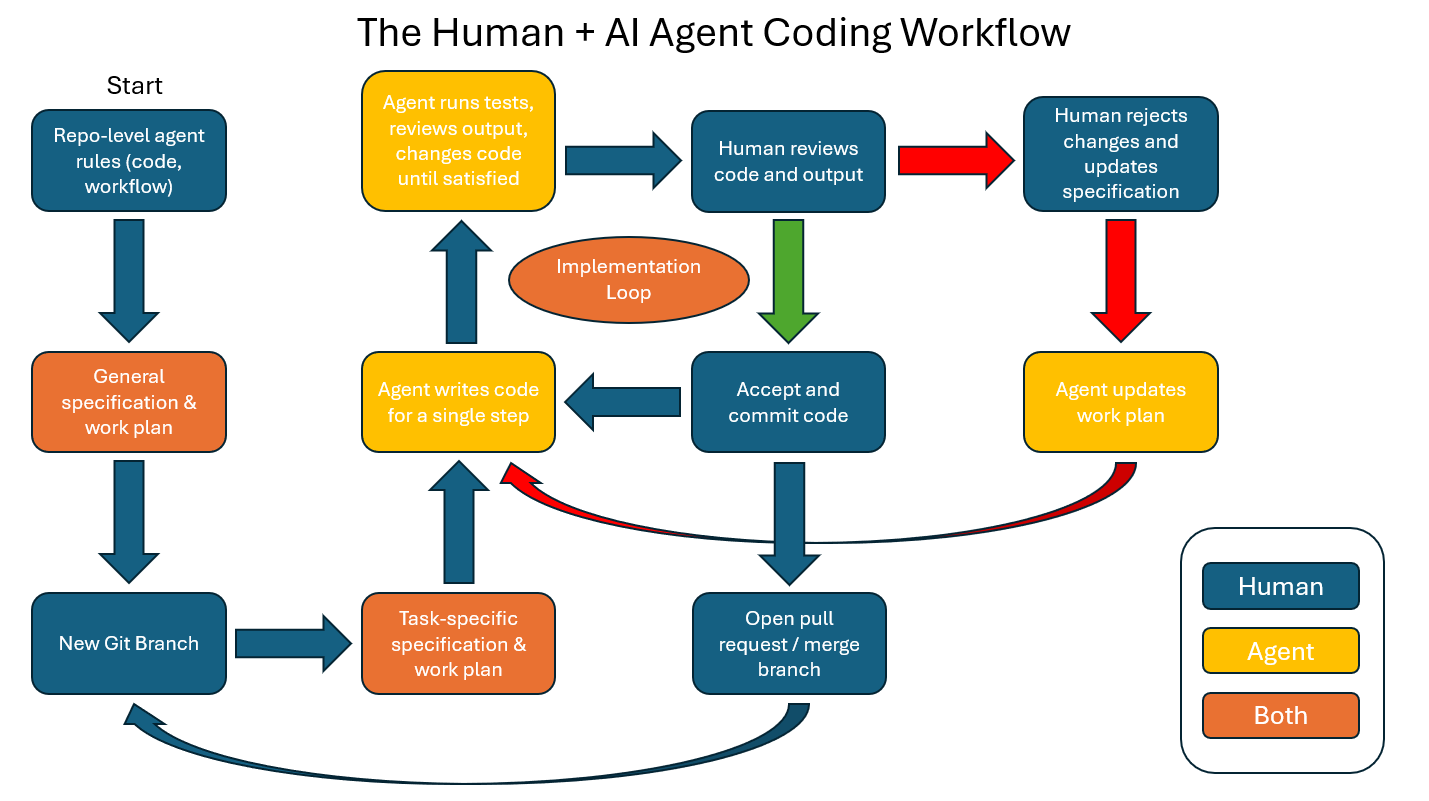 Github: john-e-moore/agentic-project-starter: Starter for coding a project with an AI agent
Github: john-e-moore/agentic-project-starter: Starter for coding a project with an AI agent
The Agent Directory
The agent directory is where we store context for the AI agent. Context just means relevant information. A major key to making sure your agent does not misbehave is making your context persistent. Persistent means it sticks around. We make our context persistent by putting it in files, not just typing it in the chat window.
Quick note: most of my projects involve lots of data transformation. Think macroeconomic models and fantasy football simulations, not website frontends. For other types of projects, things like intermediate diagnostic output may be less important. Use my workflow as a guideline.
Code rules (human-generated)
This is a YAML file that specifies how you want the agent to write code. Language and version. Formatting, logging, comments, linting, naming conventions, testing framework.
# agent/code.yaml
# Code rules for AI Agent
language: python
version: 3.12
formatting:
- line_length:88
- formatter: black
- double_quotes:true
naming_conventions:
- variables: snake_case
- classes: PascalCase
- constants: UPPER_CASE
testing:
- framework: pytest
...
Desired workflow (human)
A YAML file telling the agent how to work step by step.
# agent/workflow.yaml
# Work instructions for AI agent
guidelines:
- When planning implementation, refer to spec.md and work-plan.md for the task you are working on.
- Produce minimal, reviewable diffs.
- When data is transformed, write a copy of the data before and after to the diagnostics directory.
implementation_steps:
- Write code and tests for a single step in the work plan.
- Run code and tests.
- Review logs and diagnostic output; ask yourself if these make sense given the spec and work plan.
- If you identify a mistake, try to diagnose and fix it. If you can't, or if the task is too ambiguous, stop working and explain the issue.
- Once a step is complete, allow me to review code and commit before we move to the next step.
An initial prompt for the project and for each task (human)
For the prompt for the project itself, I put this right inside the agent directory as agent/initial-prompt.md. For each specific task (feature, bug fix), create a new directory inside the agent directory, e.g. agent/{task_name}/initial-prompt.md.
You’ll have the agent extend this prompt into a formal specification. For example,
"Below I will describe a project that I want to code. Consider my description and the other files in the agent directory, and create a specification for the project. Write it to
agent/spec.md.
I want to create a tic-tac-toe game except it’s on a 5x5 board instead of 3x3. I want it to have a graphical interface. When one player wins, animate the winning squares. …"
Specification (agent)
Once the agent generates a specification, read it over to make sure it’s exactly what you want. If it isn’t, change it yourself or instruct the agent to. The spec should include stuff from your YAML files like testing framework, acceptance criteria, various details.
Work plan (agent)
This one is easy — ask the agent to turn the specification into a step-by-step work plan and write it to agent/work-plan.md. A major key to keeping AI agents on track is giving them rules and plans to refer back to.
Version Control / Git
A comprehensive overview of Git (or version control system of your choice) is outside the scope of this article, but there are a couple of important things to mention. The difficult part of coding with an AI agent is making sure it colors inside the lines. Git is very important here.
When you do a new task / feature / bug fix, make a new Git branch, then make a new directory inside of agent/ with your prompt, spec, and work plan. Each step in the work plan should be a single logical change, not a huge diff with multiple changes. By doing this we give the agent one place to look for context about the new change, and we allow ourselves to revert back to previous commits when we or the agent goof on something. If things go really poorly, we can scrap the branch and start a new one off the most recent commit to the main branch.
Implementation Loop
This is the part that feels like magic. After putting in the work telling the agent how to work in your YAML and markdown files, you can chill in the chat window. Tell the agent to “implement the next step in the work plan.” It should then code, test, review, and notify you when it’s finished. Review what it has written, review any outputs, commit the changes, and repeat.
A note on different types of intermediate outputs and human reviews. I said earlier that many of my projects are data science-y and involve lots of data transformation. Every time data is transformed, I have my programs write data summaries and samples and such, and that’s what I have the agent (and myself) sanity check. If you are programming a website frontend, the intermediate output might be nothing. You might just have the page running locally in development mode, open in a browser, watching changes happen and clicking around.
All this to say, in the review step, do whatever makes sense for the type of program you are coding.
Red Arrow Flow
Sometimes the agent will write code that you are not satisfied with. These models are good enough now that it probably won’t be an error with the code itself. Instead, it will have misunderstood an implementation detail. There was ambiguity somewhere in the spec or work plan.
Your job now is to figure out what was not said in enough detail. Did you forget to tell it exactly how you want nulls handled? Did you forget to specify when to cache and when to re-request in your website backend? Switch the chat window from “agent” mode to “ask” mode. Tell the AI what you don’t like and ask why it did the thing the way it did. Reject the agent’s code changes. Then, either you or the agent can go back and edit the task specification. After that, update the work plan in light of the new spec and have the agent try implementing again.
If things are unresolvable, revert back to the most recent commit on the main branch and start your task over.
Conclusion
Many innovations in computer technology are abstractions. Assembly language was created so we could stop punching zeroes and ones into physical cards. Cloud systems make it so developers don’t have to worry about managing servers. Now, large language models are abstracting away programming languages themselves. Maybe that’s too extreme — it is still important to know how your language of choice does things under the hood, how to choose the right data structures and algorithms, and how to logically organize your code — but just like I never had to learn to write machine language or allocate memory, tomorrow’s engineers will not have to obsessively drill Python dictionary comprehensions and vectorization. The machines will do that for us. May our symbiosis stay mutually beneficial.